

Students News
-

Repurposed Drugs Present New Strategy for Treating..
Virtual screening of 6,218 drugs and cell-based assays identifies best therapeutic medication candidates < Figure: A schematic representation of computational drug repurposing strategy. Docking-based virtual screening can rapidly identify novel compounds for COVID-19 treatment among from the collection of approved and clinical trial drugs. > A joint research group from KAIST and Institut Pasteur Korea has identified repurposed drugs for COVID-19 treatment through virtual screening and cell-based assays. The research team suggested the strategy for virtual screening with greatly reduced false positives by incorporating pre-docking filtering based on shape similarity and post-docking filtering based on interaction similarity. This strategy will help develop therapeutic medications for COVID-19 and other antiviral diseases more rapidly. This study was reported at the Proceedings of the National Academy of Sciences of the United States of America (PNAS). Researchers screened 6,218 drugs from a collection of FDA-approved drugs or those under clinical trial and identified 38 potential repurposed drugs for COVID-19 with this strategy. Among them, seven compounds inhibited SARS-CoV-2 replication in Vero cells. Three of these drugs, emodin, omipalisib, and tipifarnib, showed anti-SARS-CoV-2 activity in human lung cells, Calu-3. Drug repurposing is a practical strategy for developing antiviral drugs in a short period of time, especially during a global pandemic. In many instances, drug repurposing starts with the virtual screening of approved drugs. However, the actual hit rate of virtual screening is low and most of the predicted drug candidates are false positives. The research group developed effective filtering algorithms before and after the docking simulations to improve the hit rates. In the pre-docking filtering process, compounds with similar shapes to the known active compounds for each target protein were selected and used for docking simulations. In the post-docking filtering process, the chemicals identified through their docking simulations were evaluated considering the docking energy and the similarity of the protein-ligand interactions with the known active compounds. The experimental results showed that the virtual screening strategy reached a high hit rate of 18.4%, leading to the identification of seven potential drugs out of the 38 drugs initially selected. “We plan to conduct further preclinical trials for optimizing drug concentrations as one of the three candidates didn’t resolve the toxicity issues in preclinical trials,” said Woo Dae Jang, one of the researchers from KAIST. “The most important part of this research is that we developed a platform technology that can rapidly identify novel compounds for COVID-19 treatment. If we use this technology, we will be able to quickly respond to new infectious diseases as well as variants of the coronavirus,” said Distinguished Professor Sang Yup Lee. This work was supported by the KAIST Mobile Clinic Module Project funded by the Ministry of Science and ICT (MSIT) and the National Research Foundation of Korea (NRF). The National Culture Collection for Pathogens in Korea provided the SARS-CoV-2 (NCCP43326). -Publication Woo Dae Jang, Sangeun Jeon, Seungtaek Kim, and Sang Yup Lee. Drugs repurposed for COVID-19 by virtual screening of 6,218 drugs and cell-based assay. Proc. Natl. Acad. Sci. U.S.A. (https://doi/org/10.1073/pnas.2024302118) -Profile Distinguished Professor Sang Yup Lee Metabolic &Biomolecular Engineering National Research Laboratory http://mbel.kaist.ac.kr Department of Chemical and Biomolecular Engineering KAIST
-

Hydrogel-Based Flexible Brain-Machine Interface
The interface is easy to insert into the body when dry, but behaves ‘stealthily’ inside the brain when wet < Figure 1. Schematic of Hydrogel Hybrid Brain-Machine Interfaces > Professor Seongjun Park’s research team and collaborators revealed a newly developed hydrogel-based flexible brain-machine interface. To study the structure of the brain or to identify and treat neurological diseases, it is crucial to develop an interface that can stimulate the brain and detect its signals in real time. However, existing neural interfaces are mechanically and chemically different from real brain tissue. This causes foreign body response and forms an insulating layer (glial scar) around the interface, which shortens its lifespan. To solve this problem, the research team developed a ‘brain-mimicking interface’ by inserting a custom-made multifunctional fiber bundle into the hydrogel body. The device is composed not only of an optical fiber that controls specific nerve cells with light in order to perform optogenetic procedures, but it also has an electrode bundle to read brain signals and a microfluidic channel to deliver drugs to the brain. The interface is easy to insert into the body when dry, as hydrogels become solid. But once in the body, the hydrogel will quickly absorb body fluids and resemble the properties of its surrounding tissues, thereby minimizing foreign body response. The research team applied the device on animal models, and showed that it was possible to detect neural signals for up to six months, which is far beyond what had been previously recorded. It was also possible to conduct long-term optogenetic and behavioral experiments on freely moving mice with a significant reduction in foreign body responses such as glial and immunological activation compared to existing devices. “This research is significant in that it was the first to utilize a hydrogel as part of a multifunctional neural interface probe, which increased its lifespan dramatically,” said Professor Park. “With our discovery, we look forward to advancements in research on neurological disorders like Alzheimer’s or Parkinson’s disease that require long-term observation.” The research was published in Nature Communications on June 8, 2021. (Title: Adaptive and multifunctional hydrogel hybrid probes for long-term sensing and modulation of neural activity) The study was conducted jointly with an MIT research team composed of Professor Polina Anikeeva, Professor Xuanhe Zhao, and Dr. Hyunwoo Yook. This research was supported by the National Research Foundation (NRF) grant for emerging research, Korea Medical Device Development Fund, KK-JRC Smart Project, KAIST Global Initiative Program, and Post-AI Project. < Figure 2. Design and Fabrication of Multifunctional Hydrogel Hybrid Probes > -Publication Park, S., Yuk, H., Zhao, R. et al. Adaptive and multifunctional hydrogel hybrid probes for long-term sensing and modulation of neural activity. Nat Commun 12, 3435 (2021). https://doi.org/10.1038/s41467-021-23802-9 -Profile Professor Seongjun Park Bio and Neural Interfaces Laboratory Department of Bio and Brain Engineering KAIST
-
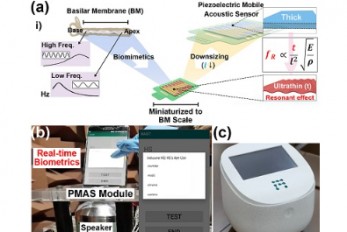
Biomimetic Resonant Acoustic Sensor Detecting Far-..
A KAIST research team led by Professor Keon Jae Lee from the Department of Materials Science and Engineering has developed a bioinspired flexible piezoelectric acoustic sensor with multi-resonant ultrathin piezoelectric membrane mimicking the basilar membrane of the human cochlea. The flexible acoustic sensor has been miniaturized for embedding into smartphones and the first commercial prototype is ready for accurate and far-distant voice detection. In 2018, Professor Lee presented the first concept of a flexible piezoelectric acoustic sensor, inspired by the fact that humans can accurately detect far-distant voices using a multi-resonant trapezoidal membrane with 20,000 hair cells. However, previous acoustic sensors could not be integrated into commercial products like smartphones and AI speakers due to their large device size. In this work, the research team fabricated a mobile-sized acoustic sensor by adopting ultrathin piezoelectric membranes with high sensitivity. Simulation studies proved that the ultrathin polymer underneath inorganic piezoelectric thin film can broaden the resonant bandwidth to cover the entire voice frequency range using seven channels. Based on this theory, the research team successfully demonstrated the miniaturized acoustic sensor mounted in commercial smartphones and AI speakers for machine learning-based biometric authentication and voice processing. (Please refer to the explanatory movie KAIST Flexible Piezoelectric Mobile Acoustic Sensor). The resonant mobile acoustic sensor has superior sensitivity and multi-channel signals compared to conventional condenser microphones with a single channel, and it has shown highly accurate and far-distant speaker identification with a small amount of voice training data. The error rate of speaker identification was significantly reduced by 56% (with 150 training datasets) and 75% (with 2,800 training datasets) compared to that of a MEMS condenser device. Professor Lee said, “Recently, Google has been targeting the ‘Wolverine Project’ on far-distant voice separation from multi-users for next-generation AI user interfaces. I expect that our multi-channel resonant acoustic sensor with abundant voice information is the best fit for this application. Currently, the mass production process is on the verge of completion, so we hope that this will be used in our daily lives very soon.” Professor Lee also established a startup company called Fronics Inc., located both in Korea and U.S. (branch office) to commercialize this flexible acoustic sensor and is seeking collaborations with global AI companies. These research results entitled “Biomimetic and Flexible Piezoelectric Mobile Acoustic Sensors with Multi-Resonant Ultrathin Structures for Machine Learning Biometrics” were published in Science Advances in 2021 (7, eabe5683). < Figure: (a) Schematic illustration of the basilar membrane-inspired flexible piezoelectric mobile acoustic sensor (b) Real-time voice biometrics based on machine learning algorithms (c) The world’s first commercial production of a mobile-sized acoustic sensor. > -Publication “Biomimetic and flexible piezoelectric mobile acoustic sensors with multiresonant ultrathin structures for machine learning biometrics,” Science Advances (DOI: 10.1126/sciadv.abe5683) -Profile Professor Keon Jae Lee Department of Materials Science and Engineering Flexible and Nanobio Device Lab http://fand.kaist.ac.kr/ KAIST
-

Natural Rainbow Colorants Microbially Produced
Integrated strategies of systems metabolic engineering and membrane engineering led to the production of natural rainbow colorants comprising seven natural colorants from bacteria for the first time < Systems metabolic engineering was employed to construct and optimize the metabolic pathways and membrane engineering was employed to increase the production of the target colorants, successfully producing the seven natural colorants covering the complete rainbow spectrum. > A research group at KAIST has engineered bacterial strains capable of producing three carotenoids and four violacein derivatives, completing the seven colors in the rainbow spectrum. The research team integrated systems metabolic engineering and membrane engineering strategies for the production of seven natural rainbow colorants in engineered Escherichia coli strains. The strategies will be also useful for the efficient production of other industrially important natural products used in the food, pharmaceutical, and cosmetic industries. Colorants are widely used in our lives and are directly related to human health when we eat food additives and wear cosmetics. However, most of these colorants are made from petroleum, causing unexpected side effects and health problems. Furthermore, they raise environmental concerns such as water pollution from dyeing fabric in the textiles industry. For these reasons, the demand for the production of natural colorants using microorganisms has increased, but could not be readily realized due to the high cost and low yield of the bioprocesses. These challenges inspired the metabolic engineers at KAIST including researchers Dr. Dongsoo Yang and Dr. Seon Young Park, and Distinguished Professor Sang Yup Lee from the Department of Chemical and Biomolecular Engineering. The team reported the study entitled “Production of rainbow colorants by metabolically engineered Escherichia coli” in Advanced Science online on May 5. It was selected as the journal cover of the July 7 issue. This research reports for the first time the production of rainbow colorants comprising three carotenoids and four violacein derivatives from glucose or glycerol via systems metabolic engineering and membrane engineering. The research group focused on the production of hydrophobic natural colorants useful for lipophilic food and dyeing garments. First, using systems metabolic engineering, which is an integrated technology to engineer the metabolism of a microorganism, three carotenoids comprising astaxanthin (red), -carotene (orange), and zeaxanthin (yellow), and four violacein derivatives comprising proviolacein (green), prodeoxyviolacein (blue), violacein (navy), and deoxyviolacein (purple) could be produced. Thus, the production of natural colorants covering the complete rainbow spectrum was achieved. When hydrophobic colorants are produced from microorganisms, the colorants are accumulated inside the cell. As the accumulation capacity is limited, the hydrophobic colorants could not be produced with concentrations higher than the limit. In this regard, the researchers engineered the cell morphology and generated inner-membrane vesicles (spherical membranous structures) to increase the intracellular capacity for accumulating the natural colorants. To further promote production, the researchers generated outer-membrane vesicles to secrete the natural colorants, thus succeeding in efficiently producing all of seven rainbow colorants. It was even more impressive that the production of natural green and navy colorants was achieved for the first time. “The production of the seven natural rainbow colorants that can replace the current petroleum-based synthetic colorants was achieved for the first time,” said Dr. Dongsoo Yang. He explained that another important point of the research is that integrated metabolic engineering strategies developed from this study can be generally applicable for the efficient production of other natural products useful as pharmaceuticals or nutraceuticals. “As maintaining good health in an aging society is becoming increasingly important, we expect that the technology and strategies developed here will play pivotal roles in producing other valuable natural products of medical or nutritional importance,” explained Distinguished Professor Sang Yup Lee. This work was supported by the "Cooperative Research Program for Agriculture Science & Technology Development (Project No. PJ01550602)" Rural Development Administration, Republic of Korea. -Publication: Dongsoo Yang, Seon Young Park, and Sang Yup Lee. Production of rainbow colorants by metabolically engineered Escherichia coli. Advanced Science, 2100743. -Profile Distinguished Professor Sang Yup Lee Metabolic &Biomolecular Engineering National Research Laboratory http://mbel.kaist.ac.kr Department of Chemical and Biomolecular Engineering KAIST
-

Ultrafast, on-Chip PCR Could Speed Up Diagnoses du..
A rapid point-of-care diagnostic plasmofluidic chip can deliver result in only 8 minutes < Professor Ki-Hun Chung(right) and PhD candidate Byoung-Hoon Kang pose with their vacuum-charged plasmofluidic PCR chip. > Reverse transcription-polymerase chain reaction (RT-PCR) has been the gold standard for diagnosis during the COVID-19 pandemic. However, the PCR portion of the test requires bulky, expensive machines and takes about an hour to complete, making it difficult to quickly diagnose someone at a testing site. Now, researchers at KAIST have developed a plasmofluidic chip that can perform PCR in only about 8 minutes, which could speed up diagnoses during current and future pandemics. The rapid diagnosis of COVID-19 and other highly contagious viral diseases is important for timely medical care, quarantining and contact tracing. Currently, RT-PCR uses enzymes to reverse transcribe tiny amounts of viral RNA to DNA, and then amplifies the DNA so that it can be detected by a fluorescent probe. It is the most sensitive and reliable diagnostic method. But because the PCR portion of the test requires 30-40 cycles of heating and cooling in special machines, it takes about an hour to perform, and samples must typically be sent away to a lab, meaning that a patient usually has to wait a day or two to receive their diagnosis. Professor Ki-Hun Jeong at the Department of Bio and Brain Engineering and his colleagues wanted to develop a plasmofluidic PCR chip that could quickly heat and cool miniscule volumes of liquids, allowing accurate point-of-care diagnoses in a fraction of the time. The research was reported in ACS Nano on May 19. The researchers devised a postage stamp-sized polydimethylsiloxane chip with a microchamber array for the PCR reactions. When a drop of a sample is added to the chip, a vacuum pulls the liquid into the microchambers, which are positioned above glass nanopillars with gold nanoislands. Any microbubbles, which could interfere with the PCR reaction, diffuse out through an air-permeable wall. When a white LED is turned on beneath the chip, the gold nanoislands on the nanopillars quickly convert light to heat, and then rapidly cool when the light is switched off. The researchers tested the device on a piece of DNA containing a SARS-CoV-2 gene, accomplishing 40 heating and cooling cycles and fluorescence detection in only 5 minutes, with an additional 3 minutes for sample loading. The amplification efficiency was 91%, whereas a comparable conventional PCR process has an efficiency of 98%. With the reverse transcriptase step added prior to sample loading, the entire testing time with the new method could take 10-13 minutes, as opposed to about an hour for typical RT-PCR testing. The new device could provide many opportunities for rapid point-of-care diagnostics during a pandemic, the researchers say. < Vacuum-charged plasmofluidic PCR chip for real-time nanoplasmonic on-chip PCR (left) and ultrafast thermal cycling with amplification curve of plasmids expressing SARS-CoV-2 envelope protein (right). > -Sources Ultrafast and Real-Time Nanoplasmonic On-Chip Polymerase Chain Reaction for Rapid and Quantitative Molecular Diagnostics ACS Nano (https://doi.org/10.1021/acsnano.1c02154) -Professor Ki-Hun Jeong Biophotonics Laboratory https://biophotonics.kaist.ac.kr/ Department of Bio and Brain Engineeinrg KAIST
-

Dr. Won-Joon Lee from the ADD Wins the Jeong Hun C..
< From left: KAIST PhD candidate Sok-Min Choi, Dr.Won-Joon Lee from ADD, Chong-Ho Park from Kongju National University High School, and Korea University > Dr. Won-Joon Lee from the Agency for Defense Development (ADD) became the 17th Jeong Hun Cho Award recipient. KAIST PhD candidate Sok-Min Choi from the Department of Aerospace Engineering, Master’s-PhD combined course student Hyong-Won Choi from Korea University, and Chong-Ho Park from Kongju National University High School were also selected. The award recognizes promising young scientists who makes significant achievements in the field of aerospace engineering in honor of Jeong Hun Cho, the former PhD candidate in the Department of Aerospace Engineering who died in a lab accident in May in 2003. Cho’s family endowed the award and scholarship to honor him. Three scholarship recipients from Cho’s alma mater, KAIST, Korea University, and Kongju National High School are selected every year. Dr. Lee from the ADD has conducted research on shape design methods and radar absorbing structures for unmanned aerial vehicles, publishing more than 24 articles in SCI-level journals and 17 at academic conferences. Dr. Lee was awarded 2.5 million KRW in prize money. the two students from KAIST and Korea University each received a 4 million KRW scholarship and Park received 3 million KRW.
-

T-GPS Processes a Graph with Trillion Edges on a S..
Trillion-scale graph processing simulation on a single computer presents a new concept of graph processing A KAIST research team has developed a new technology that enables to process a large-scale graph algorithm without storing the graph in the main memory or on disks. Named as T-GPS (Trillion-scale Graph Processing Simulation) by the developer Professor Min-Soo Kim from the School of Computing at KAIST, it can process a graph with one trillion edges using a single computer. Graphs are widely used to represent and analyze real-world objects in many domains such as social networks, business intelligence, biology, and neuroscience. As the number of graph applications increases rapidly, developing and testing new graph algorithms is becoming more important than ever before. Nowadays, many industrial applications require a graph algorithm to process a large-scale graph (e.g., one trillion edges). So, when developing and testing graph algorithms such for a large-scale graph, a synthetic graph is usually used instead of a real graph. This is because sharing and utilizing large-scale real graphs is very limited due to their being proprietary or being practically impossible to collect. Conventionally, developing and testing graph algorithms is done via the following two-step approach: generating and storing a graph and executing an algorithm on the graph using a graph processing engine. The first step generates a synthetic graph and stores it on disks. The synthetic graph is usually generated by either parameter-based generation methods or graph upscaling methods. The former extracts a small number of parameters that can capture some properties of a given real graph and generates the synthetic graph with the parameters. The latter upscales a given real graph to a larger one so as to preserve the properties of the original real graph as much as possible. The second step loads the stored graph into the main memory of the graph processing engine such as Apache GraphX and executes a given graph algorithm on the engine. Since the size of the graph is too large to fit in the main memory of a single computer, the graph engine typically runs on a cluster of several tens or hundreds of computers. Therefore, the cost of the conventional two-step approach is very high. The research team solved the problem of the conventional two-step approach. It does not generate and store a large-scale synthetic graph. Instead, it just loads the initial small real graph into main memory. Then, T-GPS processes a graph algorithm on the small real graph as if the large-scale synthetic graph that should be generated from the real graph exists in main memory. After the algorithm is done, T-GPS returns the exactly same result as the conventional two-step approach. The key idea of T-GPS is generating only the part of the synthetic graph that the algorithm needs to access on the fly and modifying the graph processing engine to recognize the part generated on the fly as the part of the synthetic graph actually generated. The research team showed that T-GPS can process a graph of 1 trillion edges using a single computer, while the conventional two-step approach can only process of a graph of 1 billion edges using a cluster of eleven computers of the same specification. Thus, T-GPS outperforms the conventional approach by 10,000 times in terms of computing resources. The team also showed that the speed of processing an algorithm in T-GPS is up to 43 times faster than the conventional approach. This is because T-GPS has no network communication overhead, while the conventional approach has a lot of communication overhead among computers. Professor Kim believes that this work will have a large impact on the IT industry where almost every area utilizes graph data, adding, “T-GPS can significantly increase both the scale and efficiency of developing a new graph algorithm.” This work was supported by the National Research Foundation (NRF) of Korea and Institute of Information & communications Technology Planning & Evaluation (IITP). -Publication: Park, H., et al. (2021) “Trillion-scale Graph Processing Simulation based on Top-Down Graph Upscaling,” IEEE ICDE 2021, Chania, Greece, Apr. 19-22, 2021. Available online at https://conferences.computer.org/icdepub -Profile: Min-Soo Kim Associate Professor http://infolab.kaist.ac.kr School of Computing KAIST
-
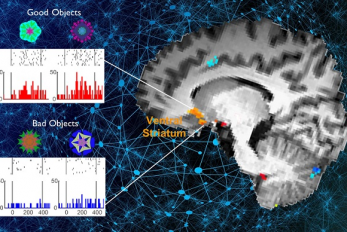
What Guides Habitual Seeking Behavior Explained
A new role of the ventral striatum explains habitual seeking behavior Researchers have been investigating how the brain controls habitual seeking behaviors such as addiction. A recent study by Professor Sue-Hyun Lee from the Department of Bio and Brain Engineering revealed that a long-term value memory maintained in the ventral striatum in the brain is a neural basis of our habitual seeking behavior. This research was conducted in collaboration with the research team lead by Professor Hyoung F. Kim from Seoul National University. Given that addictive behavior is deemed a habitual one, this research provides new insights for developing therapeutic interventions for addiction. Habitual seeking behavior involves strong stimulus responses, mostly rapid and automatic ones. The ventral striatum in the brain has been thought to be important for value learning and addictive behaviors. However, it was unclear if the ventral striatum processes and retains long-term memories that guide habitual seeking. Professor Lee’s team reported a new role of the human ventral striatum where long-term memory of high-valued objects are retained as a single representation and may be used to evaluate visual stimuli automatically to guide habitual behavior. < The ventral striatum shows increased responses to high-valued objects (good objects) after habitual seeking training. > “Our findings propose a role of the ventral striatum as a director that guides habitual behavior with the script of value information written in the past,” said Professor Lee. The research team investigated whether learned values were retained in the ventral striatum while the subjects passively viewed previously learned objects in the absence of any immediate outcome. Neural responses in the ventral striatum during the incidental perception of learned objects were examined using fMRI and single-unit recording. The study found significant value discrimination responses in the ventral striatum after learning and a retention period of several days. Moreover, the similarity of neural representations for good objects increased after learning, an outcome positively correlated with the habitual seeking response for good objects. “These findings suggest that the ventral striatum plays a role in automatic evaluations of objects based on the neural representation of positive values retained since learning, to guide habitual seeking behaviors,” explained Professor Lee. “We will fully investigate the function of different parts of the entire basal ganglia including the ventral striatum. We also expect that this understanding may lead to the development of better treatment for mental illnesses related to habitual behaviors or addiction problems.” This study, supported by the National Research Foundation of Korea, was reported at Nature Communications (https://doi.org/10.1038/s41467-021-22335-5.) -Profile Professor Sue-Hyun Lee Department of Bio and Brain Engineering Memory and Cognition Laboratory http://memory.kaist.ac.kr/lecture KAIST
-
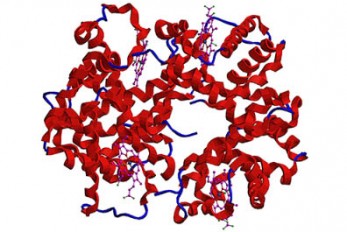
Microbial Production of a Natural Red Colorant Car..
Metabolic engineering and computer-simulated enzyme engineering led to the production of carminic acid, a natural red colorant, from bacteria for the first time < Figure: A schematic biosynthetic pathway for the production of carminic acid from glucose. Biochemical reaction analysis and computer simulation-assisted enzyme engineering was employed to identify and improve the enzymes (DnrFP217K and GtCGTV93Q/Y193F) responsible for the latter two reactions. > A research group at KAIST has engineered a bacterium capable of producing a natural red colorant, carminic acid, which is widely used for food and cosmetics. The research team reported the complete biosynthesis of carminic acid from glucose in engineered Escherichia coli. The strategies will be useful for the design and construction of biosynthetic pathways involving unknown enzymes and consequently the production of diverse industrially important natural products for the food, pharmaceutical, and cosmetic industries. Carminic acid is a natural red colorant widely being used for products such as strawberry milk and lipstick. However, carminic acid has been produced by farming cochineals, a scale insect which only grows in the region around Peru and Canary Islands, followed by complicated multi-step purification processes. Moreover, carminic acid often contains protein contaminants that cause allergies so many people are unwilling to consume products made of insect-driven colorants. On that account, manufacturers around the world are using alternative red colorants despite the fact that carminic acid is one of the most stable natural red colorants. These challenges inspired the metabolic engineering research group at KAIST to address this issue. Its members include postdoctoral researchers Dongsoo Yang and Woo Dae Jang, and Distinguished Professor Sang Yup Lee of the Department of Chemical and Biomolecular Engineering. This study entitled “Production of carminic acid by metabolically engineered Escherichia coli” was published online in the Journal of the American Chemical Society (JACS) on April 2. This research reports for the first time the development of a bacterial strain capable of producing carminic acid from glucose via metabolic engineering and computer simulation-assisted enzyme engineering. The research group optimized the type II polyketide synthase machinery to efficiently produce the precursor of carminic acid, flavokermesic acid. Since the enzymes responsible for the remaining two reactions were neither discovered nor functional, biochemical reaction analysis was performed to identify enzymes that can convert flavokermesic acid into carminic acid. Then, homology modeling and docking simulations were performed to enhance the activities of the two identified enzymes. The team could confirm that the final engineered strain could produce carminic acid directly from glucose. The C-glucosyltransferase developed in this study was found to be generally applicable for other natural products as showcased by the successful production of an additional product, aloesin, which is found in aloe leaves. “The most important part of this research is that unknown enzymes for the production of target natural products were identified and improved by biochemical reaction analyses and computer simulation-assisted enzyme engineering,” says Dr. Dongsoo Yang. He explained the development of a generally applicable C-glucosyltransferase is also useful since C-glucosylation is a relatively unexplored reaction in bacteria including Escherichia coli. Using the C-glucosyltransferase developed in this study, both carminic acid and aloesin were successfully produced from glucose. “A sustainable and insect-free method of producing carminic acid was achieved for the first time in this study. Unknown or inefficient enzymes have always been a major problem in natural product biosynthesis, and here we suggest one effective solution for solving this problem. As maintaining good health in the aging society is becoming increasingly important, we expect that the technology and strategies developed here will play pivotal roles in producing other valuable natural products of medical or nutritional importance,” said Distinguished Professor Sang Yup Lee. This work was supported by the Technology Development Program to Solve Climate Changes on Systems Metabolic Engineering for Biorefineries of the Ministry of Science and ICT (MSIT) through the National Research Foundation (NRF) of Korea and the KAIST Cross-Generation Collaborative Lab project; Sang Yup Lee and Dongsoo Yang were also supported by Novo Nordisk Foundation in Denmark. Publication: Dongsoo Yang, Woo Dae Jang, and Sang Yup Lee. Production of carminic acid by metabolically engineered Escherichia coli. at the Journal of the American Chemical Society. https://doi.org.10.1021/jacs.0c12406 Profile: Sang Yup Lee, PhD Distinguished Professor leesy@kaist.ac.kr http://mbel.kaist.ac.kr Metabolic &Biomolecular Engineering National Research Laboratory Department of Chemical and Biomolecular Engineering KAIST
-
Identification of How Chemotherapy Drug Works Coul..
< Professor Yoosik Kim and PhD candidate Yongsuk Ku > The chemotherapy drug decitabine is commonly used to treat patients with blood cancers, but its response rate is somewhat low. Researchers have now identified why this is the case, opening the door to more personalized cancer therapies for those with these types of cancers, and perhaps further afield. Researchers have identified the genetic and molecular mechanisms within cells that make the chemotherapy drug decitabine—used to treat patients with myelodysplastic syndrome (MDS) and acute myeloid leukemia (AML) —work for some patients but not others. The findings should assist clinicians in developing more patient-specific treatment strategies. The findings were published in the Proceedings of the National Academies of Science on March 30. The chemotherapy drug decitabine, also known by its brand name Dacogen, works by modifying our DNA that in turn switches on genes that stop the cancer cells from growing and replicating. However, decitabine’s response rate is somewhat low (showing improvement in just 30-35% of patients), which leaves something of a mystery as to why it works well for some patients but not for others. To find out why this happens, researchers from the KAIST investigated the molecular mediators that are involved with regulating the effects of the drug. Decitabine works to activate the production of endogenous retroviruses (ERVs), which in turn induces an immune response. ERVs are viruses that long ago inserted dormant copies of themselves into the human genome. Decitabine in essence, ‘reactivates’ these viral elements and produces double-stranded RNAs (dsRNAs) that the immune system views as a foreign body. “However, the mechanisms involved in this process, in particular how production and transport of these ERV dsRNAs were regulated within the cell were understudied,” said corresponding author Yoosik Kim, professor in the Department of Chemical and Biomolecular Engineering at KAIST. “So to explain why decitabine works in some patients but not others, we investigated what these molecular mechanisms were,” added Kim. To do so, the researchers used image-based RNA interference (RNAi) screening. This is a relatively new technique in which specific sequences within a genome are knocked out of action or “downregulated.” Large-scale screening, which can be performed in cultured cells or within live organisms, works to investigate the function of different genes. The KAIST researchers collaborated with the Institut Pasteur Korea to analyze the effect of downregulating genes that recognize ERV dsRNAs and could be involved in the cellular response to decitabine. < Schematic diagram of the molecular mechanism of decitabine. Differences in immune responses in the body according to the expression of Staufen1 and TINCR. > From these initial screening results, they performed an even more detailed downregulation screening analysis. Through the screening, they were able to identify two particular gene sequences involved in the production of an RNA-binding protein called Staufen1 and the production of a strand of RNA that does not in turn produce any proteins called TINCR that play a key regulatory role in response to the drug. Staufen1 binds directly to dsRNAs and stabilizes them in concert with the TINCR. If a patient is not producing sufficient Staufen1 and TINCR, then the dsRNA viral mimics quickly degrade before the immune system can spot them. And, crucially for cancer therapy, this means that patients with lower expression (activation) of these sequences will show inferior response to decitabine. Indeed, the researchers confirmed that MDS/AML patients with low Staufen1 and TINCR expression did not benefit from decitabine therapy. “We can now isolate patients who will not benefit from the therapy and direct them to a different type of therapy,” said first author Yongsuk Ku. “This serves as an important step toward developing a patient-specific treatment cancer strategy.” As the researchers used patient samples taken from bone marrow, the next step will be to try to develop a testing method that can identify the problem from just blood samples, which are much easier to acquire from patients. The team plans to investigate if the analysis can be extended to patients with solid tumors in addition to those with blood cancers. -Profile Professor Yoosik Kim https://qcbio.kaist.ac.kr/ Department of Chemical and Biomolecular Engineering KAIST -Publication Noncanonical immune response to the inhibition of DNA methylation by Staufen1 via stabilization of endogenous retrovirus RNAs, PNAS
-

Plasma Jets Stabilize Water to Splash Less
< High-speed shadowgraph movie of water surface deformations induced by plasma impingement. > A study by KAIST researchers revealed that an ionized gas jet blowing onto water, also known as a ‘plasma jet’, produces a more stable interaction with the water’s surface compared to a neutral gas jet. This finding reported in the April 1 issue of Nature will help improve the scientific understanding of plasma-liquid interactions and their practical applications in a wide range of industrial fields in which fluid control technology is used, including biomedical engineering, chemical production, and agriculture and food engineering. Gas jets can create dimple-like depressions in liquid surfaces, and this phenomenon is familiar to anyone who has seen the cavity produced by blowing air through a straw directly above a cup of juice. As the speed of the gas jet increases, the cavity becomes unstable and starts bubbling and splashing. “Understanding the physical properties of interactions between gases and liquids is crucial for many natural and industrial processes, such as the wind blowing over the surface of the ocean, or steelmaking methods that involve blowing oxygen over the top of molten iron,” explained Professor Wonho Choe, a physicist from KAIST and the corresponding author of the study. However, despite its scientific and practical importance, little is known about how gas-blown liquid cavities become deformed and destabilized. In this study, a group of KAIST physicists led by Professor Choe and the team’s collaborators from Chonbuk National University in Korea and the Jožef Stefan Institute in Slovenia investigated what happens when an ionized gas jet, also known as a ‘plasma jet’, is blown over water. A plasma jet is created by applying high voltage to a nozzle as gas flows through it, which causes the gas to be weakly ionized and acquire freely-moving charged particles. The research team used an optical technique combined with high-speed imaging to observe the profiles of the water surface cavities created by both neutral helium gas jets and weakly ionized helium gas jets. They also developed a computational model to mathematically explain the mechanisms behind their experimental discovery. The researchers demonstrated for the first time that an ionized gas jet has a stabilizing effect on the water’s surface. They found that certain forces exerted by the plasma jet make the water surface cavity more stable, meaning there is less bubbling and splashing compared to the cavity created by a neutral gas jet. Specifically, the study showed that the plasma jet consists of pulsed waves of gas ionization propagating along the water’s surface so-called ‘plasma bullets’ that exert more force than a neutral gas jet, making the cavity deeper without becoming destabilized. “This is the first time that this phenomenon has been reported, and our group considers this as a critical step forward in our understanding of how plasma jets interact with liquid surfaces. We next plan to expand this finding through more case studies that involve diverse plasma and liquid characteristics,” said Professor Choe. This work was supported by KAIST as part of the High-Risk and High-Return Project, the National Research Foundation of Korea (NRF), and the Slovenian Research Agency (ARRS). < Cavity formation at the water’s surface subjected to a neutral helium gas jet (left) and a weakly ionized helium gas jet (right). > Image Credit: Professor Wonho Choe, KAIST Usage Restrictions: News organizations may use or redistribute these materials, with proper attribution, as part of news coverage of this paper only. Publication: Park, S., et al. (2021) Stabilization of liquid instabilities with ionized gas jets. Nature, Vol. No. 592, Issue No. 7852, pp. 49-53. Available online at https://doi.org/10.1038/s41586-021-03359-9 Profile: Wonho Choe, Ph.D. Professor wchoe@kaist.ac.kr https://gdpl.kaist.ac.kr/ Gas Discharge Physics Laboratory (GDPL) Department of Nuclear and Quantum Engineering Department of Physics Impurity and Edge Plasma Research Center (IERC) http://kaist.ac.kr/en/ Korea Advanced Institute of Science and Technology (KAIST) Daejeon, Republic of Korea (END)
-

Centrifugal Multispun Nanofibers Put a New Spin on..
KAIST researchers have developed a novel nanofiber production technique called ‘centrifugal multispinning’ that will open the door for the safe and cost-effective mass production of high-performance polymer nanofibers. This new technique, which has shown up to a 300 times higher nanofiber production rate per hour than that of the conventional electrospinning method, has many potential applications including the development of face mask filters for coronavirus protection. Nanofibers make good face mask filters because their mechanical interactions with aerosol particles give them a greater ability to capture more than 90% of harmful particles such as fine dust and virus-containing droplets. The impact of the COVID-19 pandemic has further accelerated the growing demand in recent years for a better kind of face mask. A polymer nanofiber-based mask filter that can more effectively block harmful particles has also been in higher demand as the pandemic continues. ‘Electrospinning’ has been a common process used to prepare fine and uniform polymer nanofibers, but in terms of safety, cost-effectiveness, and mass production, it has several drawbacks. The electrospinning method requires a high-voltage electric field and electrically conductive target, and this hinders the safe and cost-effective mass production of polymer nanofibers. In response to this shortcoming, ‘centrifugal spinning’ that utilizes centrifugal force instead of high voltage to produce polymer nanofibers has been suggested as a safer and more cost-effective alternative to the electrospinning. Easy scalability is another advantage, as this technology only requires a rotating spinneret and a collector. However, since the existing centrifugal force-based spinning technology employs only a single rotating spinneret, productivity is limited and not much higher than that of some advanced electrospinning technologies such as ‘multi-nozzle electrospinning’ and ‘nozzleless electrospinning.’ This problem persists even when the size of the spinneret is increased. Inspired by these limitations, a research team led by Professor Do Hyun Kim from the Department of Chemical and Biomolecular Engineering at KAIST developed a centrifugal multispinning spinneret with mass-producibility, by sectioning a rotating spinneret into three sub-disks. This study was published as a front cover article of ACS Macro Letters, Volume 10, Issue 3 in March 2021. Using this new centrifugal multispinning spinneret with three sub-disks, the lead author of the paper PhD candidate Byeong Eun Kwak and his fellow researchers Hyo Jeong Yoo and Eungjun Lee demonstrated the gram-scale production of various polymer nanofibers with a maximum production rate of up to 25 grams per hour, which is approximately 300 times higher than that of the conventional electrospinning system. The production rate of up to 25 grams of polymer nanofibers per hour corresponds to the production rate of about 30 face mask filters per day in a lab-scale manufacturing system. By integrating the mass-produced polymer nanofibers into the form of a mask filter, the researchers were able to fabricate face masks that have comparable filtration performance with the KF80 and KF94 face masks that are currently available in the Korean market. The KF80 and KF94 masks have been approved by the Ministry of Food and Drug Safety of Korea to filter out at least 80% and 94% of harmful particles respectively. “When our system is scaled up from the lab scale to an industrial scale, the large-scale production of centrifugal multispun polymer nanofibers will be made possible, and the cost of polymer nanofiber-based face mask filters will also be lowered dramatically,” Kwak explained. This work was supported by the KAIST-funded Global Singularity Research Program for 2020. < Figure. (A) Schematic illustration of the centrifugal multispinning polymer nanofiber production process. (B) The polymer nanofibers spun by the system. The increase of the number of sub-disk shows the proportional enhancement of the productivity. (C) Face masks and mask filters fabricated using mass-produced nanofibers (inset). > < Image. Journal Cover > Publication: Byeong Eun Kwak, Hyo Jeong Yoo, Eungjun Lee, and Do Hyun Kim. (2021) Large-Scale Centrifugal Multispinning Production of Polymer Micro- and Nanofibers for Mask Filter Application with a Potential of Cospinning Mixed Multicomponent Fibers. ACS Macro Letters, Volume No. 10, Issue No. 3, pp. 382-388. Available online at https://doi.org/10.1021/acsmacrolett.0c00829 Profile: Do Hyun Kim, Sc.D. Professor dohyun.kim@kaist.edu http://procal.kaist.ac.kr/ Process Analysis Laboratory Department of Chemical and Biomolecular Engineering https:/kaist.ac.kr/en/ Korea Advanced Institute of Science and Technology (KAIST) Daejeon 34141, Korea (END)
![]()
291 Daehak-ro, Yuseong-gu, Daejeon, Korea 34141
KAIST College of Engineering
T.+82-42-350-2114
F.+82-42-350-2210 (2220)
ⓒ KAIST College of Engineering. All rights reserved.